Executive Summary
- The Risk: Algorithmic bias isn't just a PR nightmare; it produces incorrect business logic. A model that hallucinates facts or discriminates in hiring is a broken product.
- The Method: We advocate for RLHF (Reinforcement Learning from Human Feedback) as the primary mechanism for aligning models with corporate values.
- The Compliance: With the EU AI Act coming into force, "Explainability" (XAI) is no longer optional—it is a legal requirement for high-risk systems.

In the past, "Ethics" in technology was often relegated to a slide in the annual compliance training. In the age of Generative AI, Ethics has become hard engineering.
When an LLM generates a response, it is drawing from a probabilistic distribution of the entire internet. That distribution contains brilliance, but it also contains bias, toxicity, and falsehoods. "Aligning" the model means forcing it to reject the latter.
1. The Alignment Problem
You cannot program ethics with `if/else` statements. The world is too nuanced. Instead, we use a technique called RLHF (Reinforcement Learning from Human Feedback).
This process involves human operators ranking model outputs.
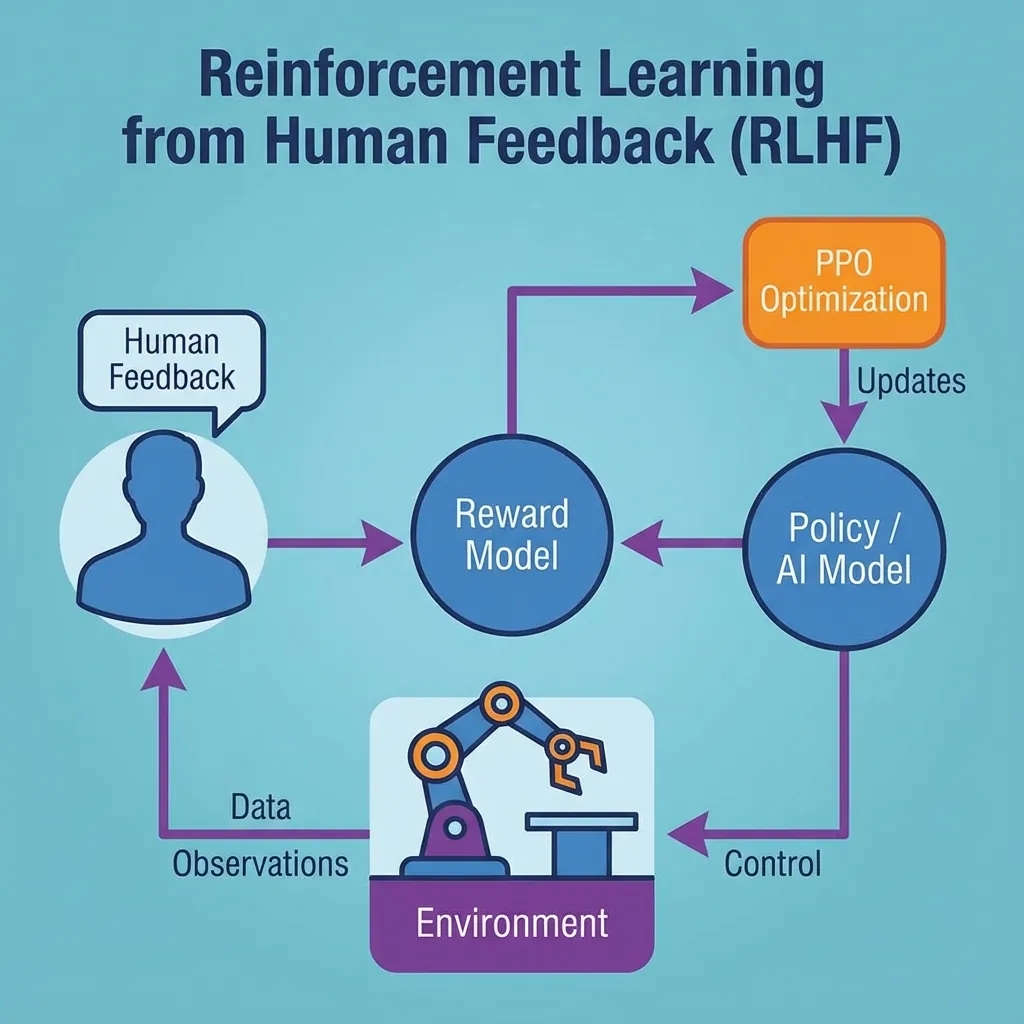
By collecting thousands of these "preference pairs" (Response A is better than Response B), we train a secondary "Reward Model" that acts as a moral compass for the main AI. This is how we ensure your AI Brand Ambassador doesn't start spewing political hate speech.
2. Hallucination is a Feature, Not a Bug
Technically, LLMs are "stochastic parrots." They do not know truth; they know probability. When they "hallucinate," they are simply predicting a low-probability token that happens to be factually wrong.
Mitigation Strategy: Grounding.
We never let an Enterprise LLM answer from its own memory. We force it to answer only using the data we provide in the Retrieval context. If the answer isn't in your documents, the model is trained to say "I don't know" rather than making up a plausible lie.
3. Explainability (The "Black Box" Issue)
If an AI denies a loan application, can you explain why? Under GDPR and the EU AI Act, you must.
This is technically difficult with Deep Learning. However, by using Chain-of-thought (CoT) prompting, we can force the model to "show its work."
Thinking:
1. Applicant income is $50k.
2. Debt-to-income ratio is 45%.
3. Policy threshold is 40%.
Conclusion: Deny loan.By capturing this internal monologue, we create an audit trail that satisfies both regulators and customers.
Conclusion
Responsible AI is not about slowing down. It is about building steering, brakes, and seatbelts so that you can drive fast without crashing.
ensure your AI is compliant? Get an Ethics & Bias Audit.